

Chatbot Arena LLM排名前10大模型盘点,Gemini-Exp-1121登顶!
来源:小智 智驻未来
Chatbot Arena LLM排行榜是一个用于评估和比较不同大型语言模型(LLM)性能的在线平台。它通过众包方式进行匿名、随机的对战测试,让社区成员可以直接参与到模型的评估过程中。
根据最新的Chatbot Arena LLM排行榜数据,以下是排名前10的大型语言模型(LLM):
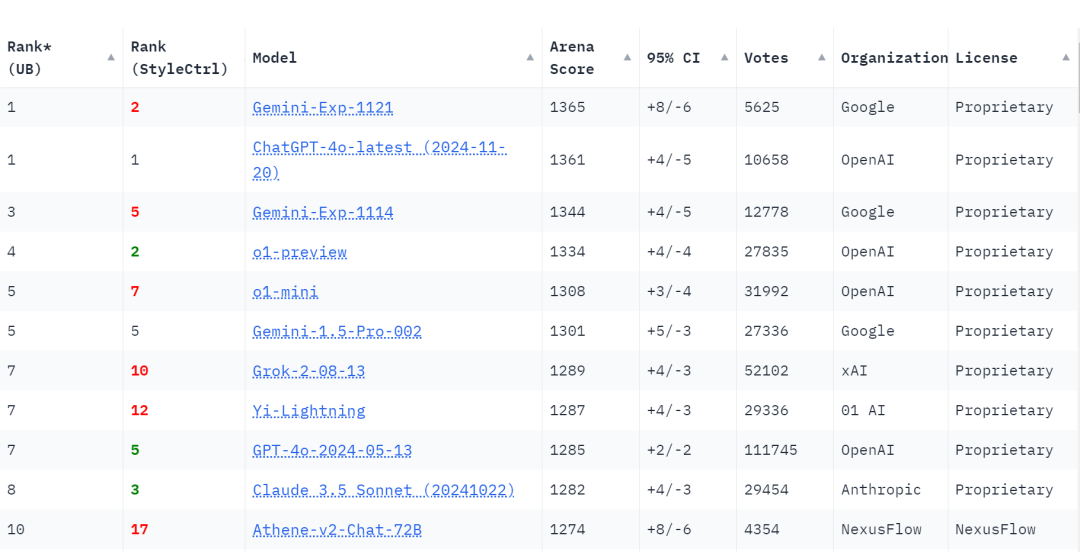
首先恭喜谷歌,凭借Gemini-Exp-1121登顶。Gemini-Exp-1121是谷歌于2024年11月21日推出的实验性AI模型.

Gemini-Exp-1121重点提升了代码、推理和视觉理解能力。与GPT-4o相比,其性能有显著提高,在代码能力上更加流畅,解决问题的能力更强,感知技能更为出色,官方称其在编码、数学和视觉理解方面比GPT-4o的性能高出20%。
例如在对同一张漫画的理解上,Gemini-Exp-1121的回答更加全面且详细,会善用小标题、重点加粗等方式来呈现内容;在经典的动物过河逻辑推理题上,Gemini-Exp-1121能够回答完全正确,而新版GPT-4o则出现了失误。
除此之外,还有Gemini-Exp-1114也入选了前10,排名第3。该模型不仅在数学、创意写作和多轮对话等基准测试中表现优异,还在复制 UI 设计、生成 SVG 代码、解决数学问题等方面展现出了高超的技术能力,同时具备情感智力和伦理推理能力。

说完谷歌,再来看看其老对手OpenAI,本次排名OpenAI有4个模型入选,都快占了半壁江山了,只能说佩服。
ChatGPT-4o-latest (2024-11-20) :
性能提升:改进了创意写作能力,能够提供更自然、更吸引人、更有针对性的写作,且相关性和可读性更强。还能更好地处理上传的文件,给出更深入的见解和更全面的回复
技术参数:该模型的上下文窗口为128000个词元,最大输出词元为16384个,训练数据截至2023年10月
应用意义:此版本的发布标志着OpenAI从之前侧重于逻辑推理的o1系列的转变,体现了其对探索人工智能模型各种能力的重视,也为用户在创意写作、文件处理等多种应用场景中提供了更优质、更强大的语言生成与理解工具.
o1-preview:
o1-preview是OpenAI推出的新系列模型之一,专为处理复杂推理和解决困难问题而设计。相比于GPT-4o,o1-preview花费更多时间进行深度思考,因此在科学、策略制定和编码等领域表现更为出色
o1-preview在编程能力上表现突出,在Codeforces编程竞赛中的排名进入了前11%。
o1-mini:
o1-mini是o1系列的轻量版模型,成本较低,响应速度更快,特别适合需要高效处理代码和基础推理任务的用户
在编程方面,o1-mini性能提升明显,特别是在代码能力、代码优化、解读代码、测试用例及说明、转码和添加注释能力方面表现出色
GPT-4o-2024-05-13:
这是OpenAI在2024年5月13日发布的新一代自然语言处理交互系统——GPT-4o。GPT-4o(“o”代表“omni”)是迈向更自然的人机交互的一步,它接受文本、音频、图像和视频的任意组合作为输入,并生成文本、音频和图像输出的任意组合
GPT-4o在英语文本和代码上的能力与GPT-4 Turbo性能相匹配,在非英语语言的文本上也有显著改进,同时在API中也更快且便宜50%
看完谷歌和OpenAI这两大巨头,再来看看马老板的xAI。


 。
。
相关文章







关注我们